Do Tor exit nodes alter your content?
The short answer : no, TOR exit nodes do not alter your content.
A recent post by @adrellias got my attention.
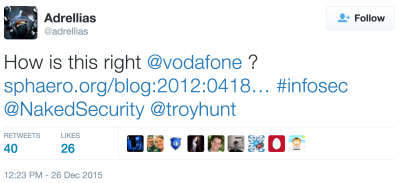
The link in the post refers to an article where a user spots a case of content (Javascript) injection by Vodafone. The details can be found in the blogpost Am I hacked? Oh, it’s just Vodafone. Needless to say this is very bad behavior by Vodafone.
Vodafone eavesdrops on your conversation, causing this to be a privacy issue. Also, the methodology used by Vodafone leads to a dangerous attack vector. If someone finds a way to alter the injected code this could lead to for example mass distribution of unwanted content, even malware.
Remember TalkTalk? ISPs are also targets of attackers.
The author of that post concludes with “In a little while we’ll all be on Tor.”.
I wanted to check if something similar happens on the Tor network. I wanted to verify if Tor exit nodes alter the HTML content.
Some remarks if you consider using Tor for daily, frequent internet use :
- You do not control, neither can easily identify who manages the end-point. It would be a very bad idea to transmit credentials through the Tor network;
- You have no control over the chosen end-point;
- Similarly, you do not know who looks at your traffic. This can also be a privacy issue. See the Tor documentation. You can also refer to the Tor Legal FAQ : “Do not examine anyone’s communications without first talking to a lawyer.”;
- Even if you use encryption, you have to be prudent to use Tor for accessing your bank account, I personally don’t use Tor for banking transactions. The transmission might be encrypted but you have to make sure that your requests go to the intended resource ;
- My test covers only a subset of all of the available Tor exit nodes.
Interested in the graphs? Scroll down to Mapping the Tor exit nodes.
The Tor network
Tor protects you by bouncing your communications around a distributed network of relays run by volunteers all around the world: it prevents somebody watching your Internet connection from learning what sites you visit, and it prevents the sites you visit from learning your physical location (from https://www.torproject.org/).
I posted on the use of Tor before
- Use privoxy and Tor for increased anonymity;
- Recursive curl with Tor on Apple OSX;
- Nmap scan through TOR
The setup
Goal
The basic goal was to
- Setup a web page on a web server.
- Retrieve that web page through a Tor proxy connection.
- Obtain a new IP through Tor (basically getting a new identity).
- Retrieving the same HTML file.
- Then comparing the output.
Proxy and Tor setup
For this test I used my previously described setup with Privoxy and Tor on an Ubuntu system.
Test web page
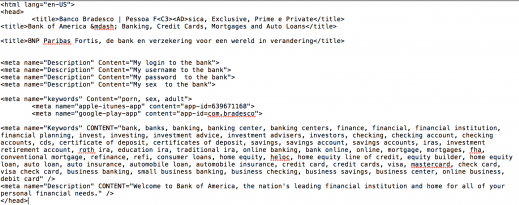
The test web page was stored on a cloud hosted machine. I included some content that would make it more enticing for an intruder to look at the content. The page contained
- meta data from Bank of America, Banco Bradesco and BNP Paribas Fortis;
- a login form from Bank of America and Banco Bradesco;
- some keywords referring to adult content
Retrieve the web page
I then wrote a short bash script that restarts the Tor service (getting a new IP, there are better ways to accomplish this but it worked), sleeps a while (to make sure the Tor tunnel is started) and then retrieves the page. I used a fake user agent for more cloaking. Once the web page was retrieved I used curl to obtain the IP address of the Tor node.
This last step basically gives away that this is “unusual” internet-behavior (normally you do not use curl to get a web page). But because the HTML content was already downloaded I did not really care about this.
#!/bin/bash export http_proxy="http://127.0.0.1:8118" for (( ; ; )) do sudo /etc/init.d/tor restart sleep 15 FNAME=`hexdump -n 16 -v -e '/1 "%02X"' /dev/urandom` wget -a torget.log --inet4-only --no-cache --user-agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:42.0) Gecko/20100101 Firefox/42.0" -O $FNAME http://REDACTED/mytrpt.html curl -s http://ifcfg.me |cut -d " " -f 5 > $FNAME.ip sleep 3 done
The above resulted for every retrieval in two files : one file containing the HTML and one file (ending in .ip) containing the IP address.
I had this script run for a couple of hours and then had a look at the results.
Analyze the results
Scripting the hash
I wrote a second bash script to analyze the retrieved files. It removed all files with no content (size 0, this can be the result of for example an unavailable exit node), calculated the MD5 hash and then looked at how many unique MD5 hashes occurred.
#!/bin/bash
echo "Delete HTML files that return empty"
EMPTYFILES=$(ls -l | grep " 0 Dec" |grep -v .ip| awk '{print $9}')
for F in $EMPTYFILES
do
rm $F
rm $F.ip
done
echo "Delete HTML files that have no IP (curl-error?)"
EMPTYFILES=$(ls -l | grep " 0 Dec" |grep .ip| awk '{print $9}'| cut -d \. -f 1)
for F in $EMPTYFILES
do
rm $F
rm $F.ip
done
# Can do md5sum for a dir but more difficult to get only md5 on HTMLfiles
echo > md5sum.log
HTMLFILES=$(ls -l | grep -v .ip | grep -v .sh | grep -v .log | awk '{print $9}')
echo "Running MD5"
for f in $HTMLFILES
do
md5=`md5sum $f | awk '{print $1}'`
echo $md5 >> md5sum.log
done
echo "Counting elements"
cat md5sum.log | grep . | wc -l
echo "Unique elements"
cat md5sum.log | grep . | sort | uniq | wc -l
echo "->"
cat md5sum.log | grep . | sort | uniq
Results
In total the HTML page was completely (meaning not empty) returned for a total of 1568 times. The resulting md5sum.log file had 1 unique entry.
Counting elements 1568 Unique elements 1 -> bda6944a104b0854b7c15a1906d7fdd5
Because all of the returned HTML content was identical the conclusion is that, at least for a basic HTML page, the Tor exit nodes do not alter the returned content.
This does not mean it does NOT happen. I only looked at a subset of exit nodes. The Tor Metrics page gives an overview of running Tor nodes. You can download the IP-list via http://torstatus.blutmagie.de/. My test also consisted of retrieving a single HTML page on a test domain. Pages coming from popular sources might render different results.
Mapping the Tor exit nodes
Because the test already gave me a list of Tor exit nodes I decided I could as well graph these results. I used a third script to run through the *.ip files, extract the IPs and enrich the file with info from Team Cymru. The request for the IP (via curl) failed on a couple of occasions, this resulted in HTML being present in the *.ip files. I detected these via the head-tag and removed these files from the results.
#!/bin/bash echo "Remove IPs with Proxy errors" HTMLIP=$(fgrep "<head>" *.ip | cut -d \: -f 1) for f in $HTMLIP do rm $f done echo "Extract IPs" IPFILES=$(ls *.ip) echo > ip.log echo > ip.uniq.whois.log echo "begin" > ip.uniq.log echo "verbose" >> ip.uniq.log for f in $IPFILES do `cat $f >> ip.log` done cat ip.log | sort | uniq | wc -l cat ip.log | sort | uniq >> ip.uniq.log echo "end" >> ip.uniq.log echo "Enrich with Cymru" cat ip.uniq.log | nc whois.cymru.com 43 > ip.uniq.whois.log
The above gives a file with unique IP addresses (ip.uniq.log) and a file with Geo-information (ip.uniq.whois.log). From the latter I can extract the countries and their occurrences with
cat ip.uniq.whois.log | awk '{print $7;}' | sort | uniq -c | sort -nr
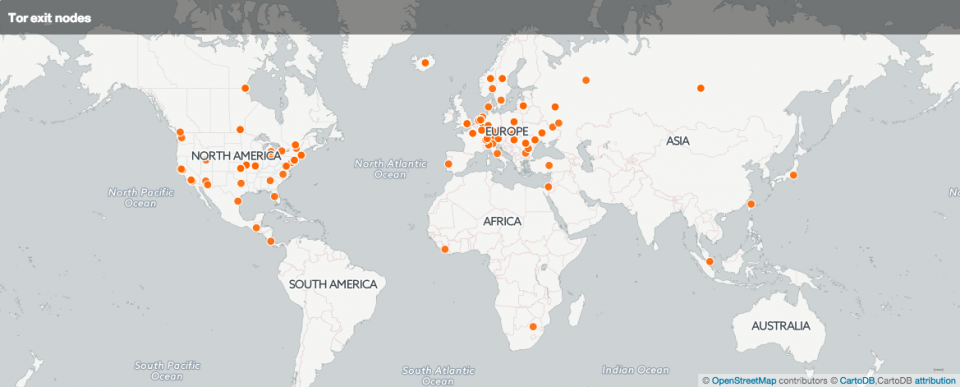
Geographic location of the Tor exit nodes
In total there were 369 unique IPs.
The majority of the Tor exit nodes is situated in the US 79 (21%), France 40 (11%), Germany 39 (11%) and Holland 36 (10%).
There were no exit nodes located in Belgium that popped up during this test.
In a previous post I visualised IP data with CartoDB. I now did the same with the list of unique exit node IPs. This resulted in this map at CartoDB.
The map is published at CartoDB or (if you allow iframes) below.
Geo location differences
A word on the difference in geo location. In the data enriched via Team Cymru I had 11 IPs located in Great Britain. The CartoDB representation showed less IPs in Great Britain. Querying the IPs in CartoDB showed that the “GB”-IPs were be located in US, Mexico, Serbia and others. I do not have an explanation for the difference. Personally I put more trust in the accuracy of the data coming from Team Cymru.
Conclusion
Based on this short test it seems that Tor exit nodes do not alter the returned HTML content. It is not possible to deduct if any eavesdropping took place at the exit node.
Also this test retrieved a web page from a test domain. Pages coming from popular domains (Google, Facebook, etc.) might give different results.
Is Tor safer than Vodafone? When it concerns un-encrypted traffic you should not make a difference between how much you trust your “normal” ISP and how much you trust a Tor exit node maintainer. Neither of them should look at your content data but this does not mean they will refrain from doing so. Additionally, some Tor exit nodes are blocked (or throttled) at content delivery networks. This might negatively influence your Internet experience.

